| |
UTF-8
From Wikipedia, the free encyclopedia
UTF-8
UTF-8 (UCS Transformation Format 8-bit[1]) is a variable-width encoding that can represent every character in the Unicode character set. It was designed for backward compatibility with ASCII and to avoid the complications of endianness and byte order marks in UTF-16 and UTF-32.
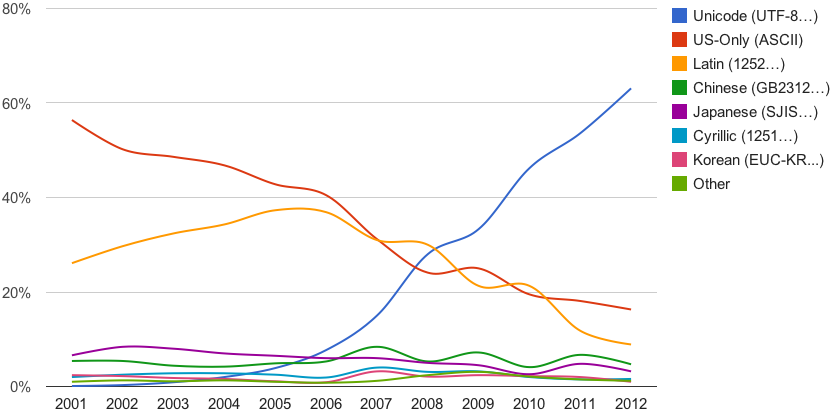
UTF-8 has become the dominant character encoding for the World-Wide Web, accounting for more than half of all Web pages.
History
By early 1992 the search was on for a good byte-stream encoding of multi-byte character sets. The draft ISO 10646 standard contained a non-required annex called UTF-1 that provided a byte-stream encoding of its 32-bit code points. This encoding was not satisfactory on performance grounds, but did introduce the notion that bytes in the range of 0 - 127 represent themselves in UTF, thereby providing backward compatibility with ASCII.
In July 1992, the X/Open committee XoJIG was looking for a better encoding. Dave Prosser of Unix System Laboratories submitted a proposal for one that had faster implementation characteristics and introduced the improvement that 7-bit ASCII characters would only represent themselves; all multibyte sequences would include only bytes where the high bit was set.
In August 1992, this proposal was circulated by an IBM X/Open representative to interested parties. Ken Thompson of the Plan 9 operating system group at Bell Labs then made a crucial modification to the encoding to allow it to be self-synchronizing, meaning that it was not necessary to read from the beginning of the string to find code point boundaries. Thompson's design was outlined on September 2, 1992, on a placemat in a New Jersey diner with Rob Pike. The following days, Pike and Thompson implemented it and updated Plan 9 to use it throughout, and then communicated their success back to X/Open.[10]
UTF-8 was first officially presented at the USENIX conference in San Diego, from January 25-29, 1993.
In November 2003 UTF-8 was restricted by RFC 3629 to four bytes in order to match the constraints of the UTF-16 character encoding.
General
Advantages
The ASCII characters are represented by themselves as single bytes that do not appear anywhere else, which makes UTF-8 work with the majority of existing APIs that take bytes strings but only treat a small number of ASCII codes specially. This removes the need to write a new Unicode version of every API, and makes it much easier to convert existing systems to UTF-8 than any other Unicode encoding.
UTF-8 is the only encoding for XML entities that does not require a BOM or an indication of the encoding.[28]
UTF-8 and UTF-16 are the standard encodings for Unicode text in HTML documents, with UTF-8 as the preferred and most used encoding.
UTF-8 strings can be fairly reliably recognized as such by a simple heuristic algorithm.[29] The probability of a random string of bytes which is not pure ASCII being valid UTF-8 is 3.9% for a two-byte sequence,[30] and decreases exponentially for longer sequences. ISO/IEC 8859-1 is even less likely to be mis-recognized as UTF-8: the only non-ASCII characters in it would have to be in sequences starting with either an accented letter or the multiplication symbol and ending with a symbol. This is an advantage that most other encodings do not have, causing errors (mojibake) if the receiving application isn't told and can't guess the correct encoding. Even word-based UTF-16 can be mistaken for byte encodings (like in the "bush hid the facts" bug).
Sorting of UTF-8 strings as arrays of unsigned bytes will produce the same results as sorting them based on Unicode code points.
Other byte-based encodings can pass through the same API. This means, however, that the encoding must be identified. Because the other encodings are unlikely to be valid UTF-8, a reliable way to implement this is to assume UTF-8 and switch to a legacy encoding only if several invalid UTF-8 byte sequences are encountered.
Disadvantages
A UTF-8 parser that is not compliant with current versions of the standard might accept a number of different pseudo-UTF-8 representations and convert them to the same Unicode output. This provides a way for information to leak past validation routines designed to process data in its eight-bit representation.[31]
|
|
)
)
)
